ChatGPT und Co. - Das Ende der Hausarbeit?
|
Workshopleitung |
|
|
Datum |
14.02.2024 |
|
Struktur der Veranstaltung |
Impulsvortrag mit Workshop |
Zusammenfassung
Im Dezember 2023 sorgte die Wirtschaftsuniversität Prag für Aufsehen, weil sie die Bachelorarbeit als zentrale Prüfungsform in betriebswirtschaftlichen Studiengängen zukünftig abschaffen wird. Ausgehend von der Fragestellung, ob wissenschaftliche Abschlussarbeiten bald obsolet werden, werden im Workshop verschiedene Aspekte generativer KI vor dem Hintergrund guter wissenschaftlicher Praxis in den Blick genommen.
Zunächst wird in die Eigenheiten und Funktionsweisen von Large Language Models (LLMs) eingeführt. ChatGPT als bekanntester Vertreter basiert wie alle anderen neuen LLMs auf der 2017 vorgestellten Transformerarchitektur. Diese Modelle führen Textoperationen auf Basis vortrainierter Daten durch. Dabei greifen sie auf eine neuronale Netzwerkstruktur zurück, welche im Laufe des Trainings ausgebildet wird. Deshalb ist es wichtig, das neuronale Netzwerk mit möglichst vielen und auch unterschiedlichen Texten zu trainieren. Auf Grundlage der eingespeisten Textdaten bildet das neuronale Netzwerk Sprache als einen Wahrscheinlichkeitsraum ab: die Textproduktion folgt einer Wahrscheinlichkeitsheuristik und wird durch die Trainingsdaten vordeterminiert. Durch eine mittels Texteingabe gestellte konkrete Anfrage (Prompt) wird die Textoperation in Gang gesetzt. Dabei kann der erwartbare Output durch den Prompt begrenzt werden, z.B. durch zusätzliche Informationen und Anweisungen. Wenig beachtet ist dabei das Problem, dass sich einige Anbieter Nutzungsrechte an den geprompteten Inhalten ausbedingen, sodass die Verwendung urheberrechtlich geschützter Materialien oder personenbezogener Daten Dritter (etwa von Probandinnen) in Prompts rechtlich bzw. wissenschaftsethisch problematisch sein kann.
Gerade bei kommerziellen Anbietern wie OpenAI (ChatGPT) sind mittlerweile kaum noch Angaben zu den Trainingsdaten verfügbar. Generell lässt sich sagen, dass für das Training verschiedene Datensammlungen verwendet werden, die im Netz verfügbare Inhalte zusammenführen, darunter Webseiten, Bücher und Artikel. Da es darum geht, allgemein ein möglichst umfassendes Konvolut an Materialien zusammenstellen, fehlt ein speziell wissenschaftlicher Zuschnitt. Ein Blick auf die Trainingsdaten des Modells GPT-3 von OpenAI verrät, dass es zu 60% mit Daten aus dem Common Crawl (gefiltert) und nur zu circa 16% aus Büchern trainiert wurde. Die Trainingsdaten werden in der Regel bereinigt und das Antwortverhalten durch human reinforced learning modifiziert, um problematische Inhalte wie Gewalt, Vorurteile, Hate Speech zu vermeiden. Nichtsdestotrotz enthalten die Trainingsdaten Fehler, Verzerrungen, Biases und Fehlrepräsentationen, welche von den Modellen dennoch teils wiedergegeben werden.
Large Language Modelle sind keine Wissens-, sondern Sprachmodelle, sie verfügen weder über Textverständnis noch Weltbewusstsein. Deshalb kommt es vor, dass LLMs Sachzusammenhänge, Informationen und Quellen halluzinieren oder erfinden (insbesondere Bender et al prägten dafür den Begriff „stochastische Papageien“). Im Einzelfall, insbesondere in Bereichen, in denen ein LLM ‚deterministisch‘ wird, kann es vorkommen, dass (nahezu) wörtliche Passagen aus den Trainingsdaten im Text reproduziert werden (Stichwort: Plagiat). Auch bei der neuen Generation der retrieval augmented LLMs, bei denen in der Textproduktion zusätzlich Informationen aus Internetabfragen genutzt werden, kann es zu deutlichen textlichen und strukturellen Analogien mit den genutzten Quellen kommen – oft in der Form nahe am Originaltext orientierter Paraphrasen.
Trotz der beeindruckenden Leistung generativer KI-Tools, Textoperationen in kurzer Zeit lösen zu können, ist übermäßiges Vertrauen gegenüber der Technologie ungerechtfertigt. Im Gegenteil muss jeder Output gründlich geprüft werden, weshalb sich der Einsatz im Rahmen wissenschaftlicher (Abschluss-)Arbeiten aufgrund der mit wissenschaftlicher Autorschaft verbundenen erhöhten Sorgfaltspflicht nur bedingt empfiehlt.
Auch die Wahl des Modells soll überlegt sein. Unterschiedliche Modelle geben unterschiedliche Antworten. Dies wird veranschaulicht, indem drei Antworten (von ChatGPT, Gemini und Perplexity) zu demselben, wortlautgleichen Prompt aufgezeigt werden. Dabei werden unterschiedliche Objektivitätsgrade der Modelle sowie ihre Wiedergabe von bestimmten Biases deutlich. Bei diesem Vergleich zeigt sich auch der Unterschied zwischen reinen, geschlossenen Sprachmodellen, die keine zusätzlichen Informationen aus dem Internet (oder einer angeschlossenen Datenbank) abrufen können und den neueren sog. Retrieval augmented LLMs, die für die Textproduktion zusätzliche Informationen aus Suchanfragen einholen können. Letztere können im Gegensatz zu geschlossenen Sprachmodellen, bei denen der Aktualitätsgrad durch den in den Trainingsdaten abgebildeten Sachstand eingefroren ist, auch auf aktuelle Informationen zugreifen. Allerdings zeigte sich, dass bei der Wiedergabe der gefundenen Informationen verschiedene Probleme auftreten können: 1. Validität/Qualität der gefundenen Quellen, 2. längere am Wortlaut der Quelle paraphrasierte Textpassagen sowie 3. Fehlattribution von Aussagen/Informationen oder Fehldarstellungen.
Inwiefern die Verwendung generativer KI-Tools wissenschaftliches Fehlverhalten darstellt, ist Gegenstand aktueller Diskussionen. Grundsätzlich gilt, dass wissenschaftliches Fehlverhalten einen vorsätzlichen oder grob fahrlässigen Verstoß gegen die Grundsätze der guten wissenschaftlichen Praxis voraussetzt. Die Leitlinien der DFG benennen explizit drei Formen wissenschaftlichen Fehlverhaltens: 1. das Erfinden von Daten, 2. das Verfälschen von Daten sowie 3. das Plagiat. Als personenbezogenes Konzept setzt wissenschaftliches Fehlverhalten die Fähigkeit zur Übernahme von Verantwortung voraus. Entsprechend sind LLMs nicht zu Fehlverhalten fähig, weil sie keine Verantwortung für die von ihnen verfassten Inhalte übernehmen können. Wenn ein Modell Fehlinformationen, Falschangaben oder (in seltenen Fällen) wörtliche Textplagiate generiert, liegt die Verantwortung somit bei der Person, die diese Texte verwendet oder wiedergibt. Bezüglich der Abgrenzung zum klassischen Plagiat folgt aus dem Umstand, dass LLMs keine Autorschaft beanspruchen können, dass KI-generierte Texte nicht plagiatfähig sind.
Aus der wahrscheinlichkeitsbasierten Funktionsweise von LLMs ergibt sich, dass sich die Erkennung von KI-generierten Texten fundamental anders gestaltet als die Erkennung von Plagiaten. Während sich klassische Plagiate gut durch einen direkten Textvergleich erkennen lassen (u.a. auch mit Unterstützung entsprechender Software), kann sich die Erkennung KI-generierter Inhalte lediglich auf die wahrscheinliche Verteilung bestimmter semantischer Merkmale in einem Text stützen. Obwohl mittlerweile auch viele Anbieter von sog. Plagiatssoftware mit KI-Erkennung werben, ist dieses Feld weiterhin prekär. Dies lässt sich u.a. daraus ableiten, dass selbst der Hersteller von ChatGPT den hauseigenen ‚Erkennungsalgorithmus‘ nach einer kurzen Testphase wieder einstellte, weil zum einen die Quote der korrekt erkannten KI-Texte von knappen 30 Prozent nicht signifikant verbessert werden konnte und zudem die Quote der false positives, also von Menschen geschriebene und fälschlich als KI-generiert bewertete Texte, mit knapp 10 Prozent sehr hoch lag. Für die Erkennung KI-generierter Texte stehen derzeit somit keine zuverlässigen Tools zur Verfügung. Allerdings können allgemeine Merkmale als Hinweise für den Einsatz generativer KI gelesen werden. Diese umfassen z.B. offenkundige Faktenfehler, oberflächliche Darstellungen, falsche und/oder inexistente Quellen, sprachliche und/oder stilistische Brüche innerhalb der Arbeit – insbesondere, wenn zum Vergleich ältere Arbeiten herangezogen werden können.
Die Frage, ob der Einsatz generativer KI-Tools in studentischen Arbeiten als wissenschaftliches Fehlverhalten betrachtet wird, sollte aktiv von Hochschulen (Leitung, Fachbereiche, Fächer usw.) adressiert werden. Die Antwort sollte sich dabei vor allem auf die mit dem Format Hausarbeit in verschiedenen Kontexten und Studienphasen verbundenen Lernziele sowie auf konkreten Einsatzszenarien beziehen. So zeigt sich etwa der Einsatz von Übersetzungstools in den meisten Fällen als unproblematisch; problematisch wird er indes, wenn die Sprachkompetenz prüfungsgegenständlich ist oder solche Tools zur Übersetzung aus Sprachen verwendet werden, die der/die Nutzer*in selbst nicht beherrscht. Ähnliches gilt für die Verwendung von LLMs zur Erstellung von Gliederungen insbesondere bei den ersten schriftlichen Prüfungsarbeiten, bei denen das sinnvolle Gliedern eines Themas gerade ein zentrales Lernziel darstellt, das auch die Grundlage dafür bildet, einen LLM-generierten Gliederungsvorschlag kritisch bewerten zu können.
Um faire Rahmenbedingungen für eine Nutzung von LLMs innerhalb der Leitlinien guter wissenschaftlicher Praxis zu schaffen, braucht es Transparenz und klar definierte Regeln (die auch mögliche Sanktionierung von Regelverstößen adressieren).
Daher kann es im Rahmen bereits bestehender Regelungen sinnvoll für Lehrende sein, sich bereits zum Beginn eines Semesters bzw. Lehrveranstaltung mit den Studierenden Zeit zu nehmen, um klare und einheitliche Vereinbarungen zum Einsatz generativer KI-Tools zu treffen (z.B. für welche Arbeitsschritte diese zugelassen sind und für welche nicht und in welcher Form der Einsatz gekennzeichnet und dokumentiert werden soll). Wichtig ist dabei, diese Vereinbarungen auch schriftlich festzuhalten und für alle Beteiligten zugänglich zu machen. Fehlen solche expliziten Vereinbarungen, kann es für Studierende ratsam sein, aktiv das Gespräch mit den Betreuenden zu suchen, um die Möglichkeit des KI-Einsatzes zu überprüfen und die damit verbundenen Modalitäten festzulegen.
Diskussion
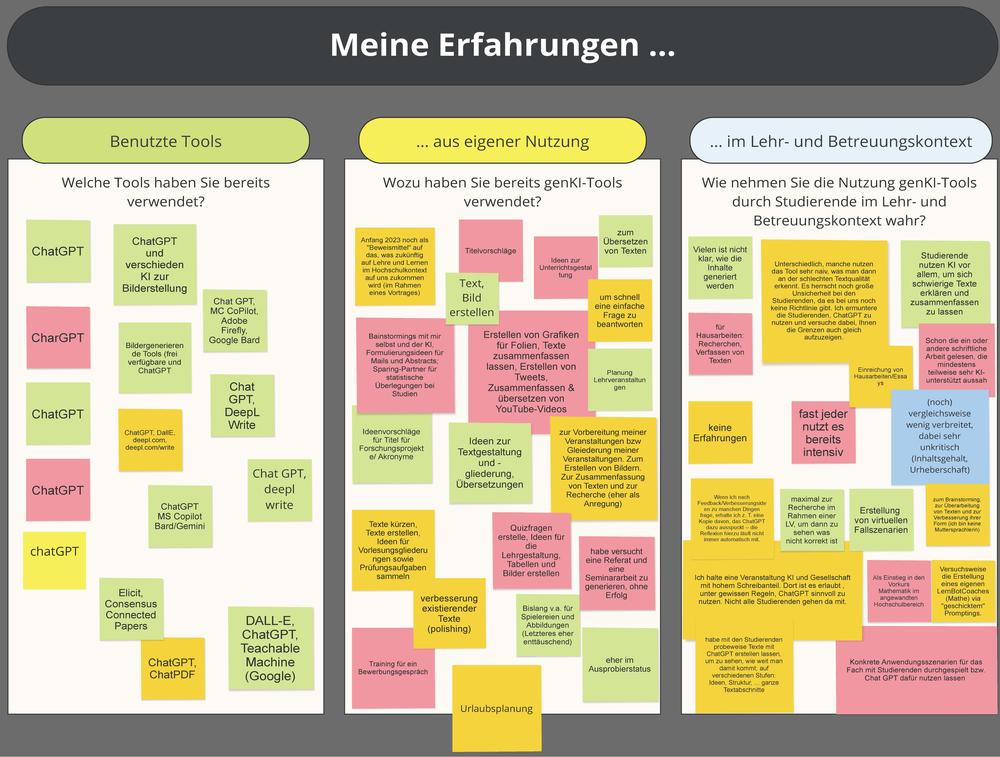
Zu Beginn des Workshops werden die Teilnehmenden ersucht, ihre Erfahrungen in Bezug auf generative KI auf einer digitalen Pinnwand festzuhalten. Dabei sind drei Spalten vorgegeben:
- Welche Tools haben Sie bereits verwendet?
- Wozu haben Sie bereits genKI-Tools verwendet?
- Wie nehmen Sie die Nutzung genKI-Tools durch Studierende im Lehr- und Betreuungskontext wahr?
Die Teilnehmenden sind demnach dazu angehalten, unterschiedliche Tools und Verwendungsarten zu differenzieren. Das Ergebnis zeigt, dass die Teilnehmenden bereits mit vielfältigen Vor-Erfahrungen in die Veranstaltung kommen (Board 1: Vorkenntnisse und Erfahrungen). Dabei wird ersichtlich, dass die Teilnehmenden die Tools für sehr unterschiedliche Zwecke nutzen: Von der klassischen Text- und Bildproduktion bis hin zum innovativen Einsatz in Lehre (z.B. zur Erstellung von Folieninhalten und Quizfragen), Forschung (z.B. Formulierung von Abstracts und Verbesserung bestehender Texte) und Karriere (z.B. Training für ein Bewerbungsgespräche). Auch die Wahrnehmung der studentischen Nutzung variiert stark und reicht von keinen Erfahrungen bis hin zum bewussten Einsatz und aktiver Promotion der Tools in der eigenen Lehre. Mit Abstand am häufigsten wird das Tool ChatGPT genannt.
Im Anschluss an einen ersten Impulsvortrag haben die Teilnehmenden die Möglichkeit, sich im Rahmen einer 20-minütigen Arbeitsphase mit Fragen zum Einsatz generativer KI in der wissenschaftlichen Textproduktion und zur Kompetenzvermittlung durch die Prüfungsform Hausarbeit auseinanderzusetzen. Dabei stehen drei Fragen im Fokus:
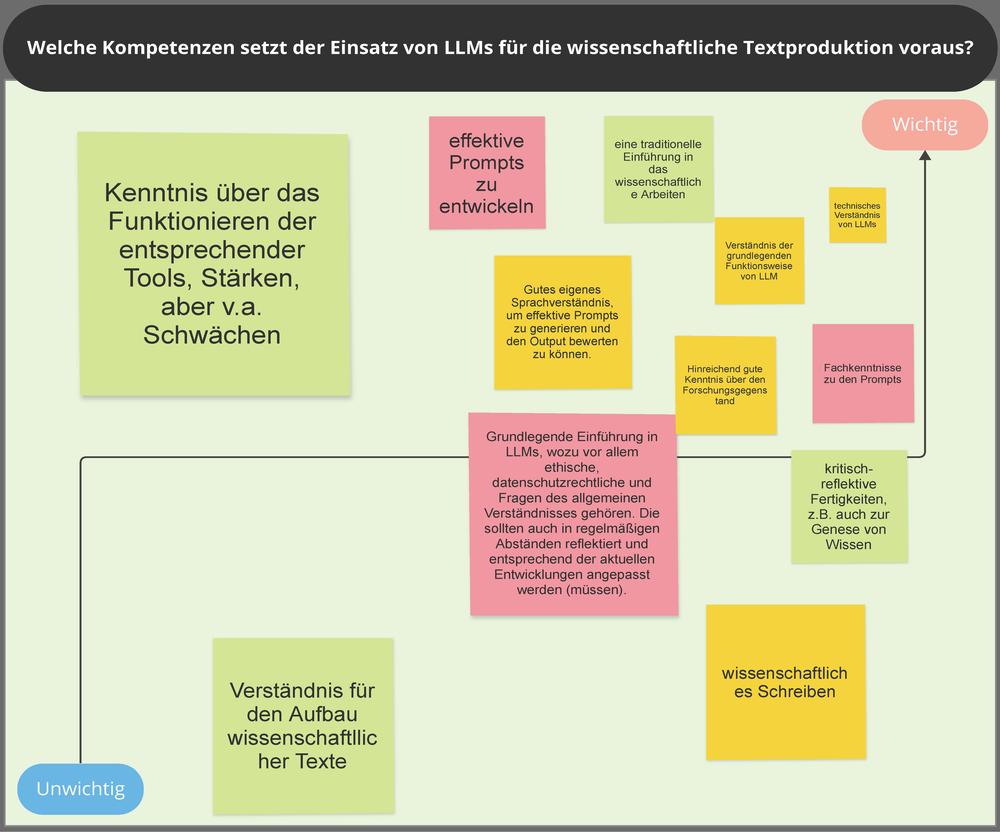
- Welche Kompetenzen setzt der Einsatz von LLMs für die wissenschaftliche Textproduktion voraus? (Board 2)
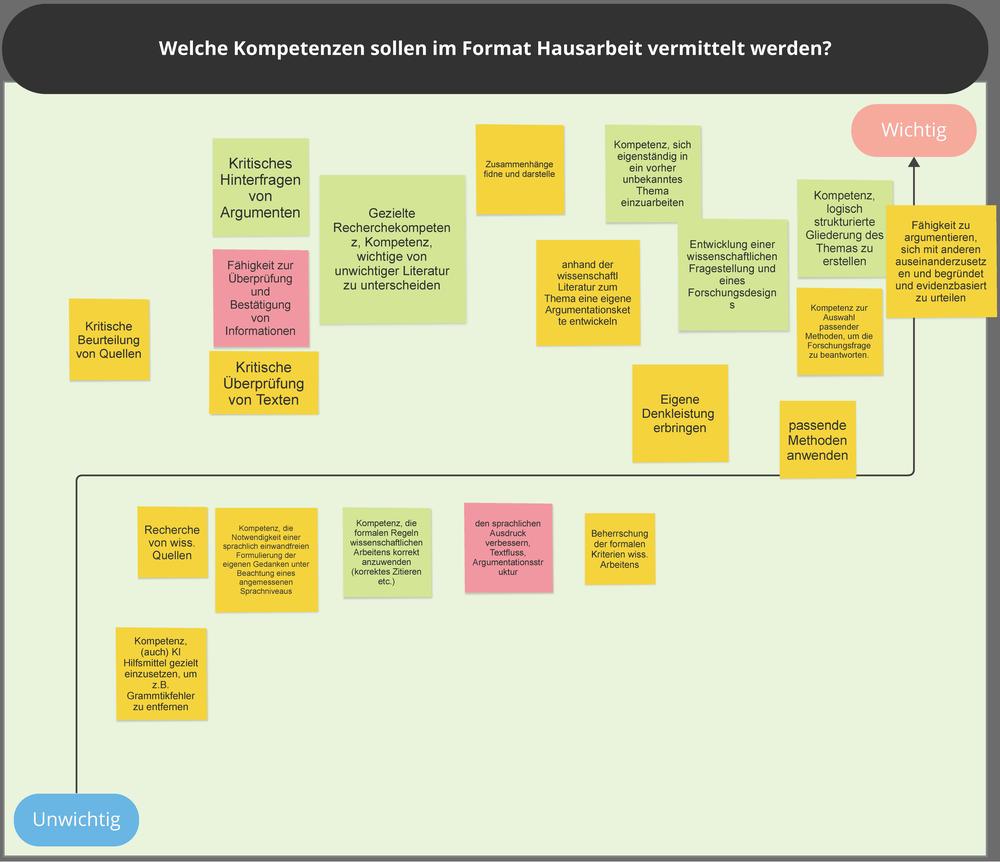
- Welche Kompetenzen sollen im Format Hausarbeit vermittelt werden? (Board 3)
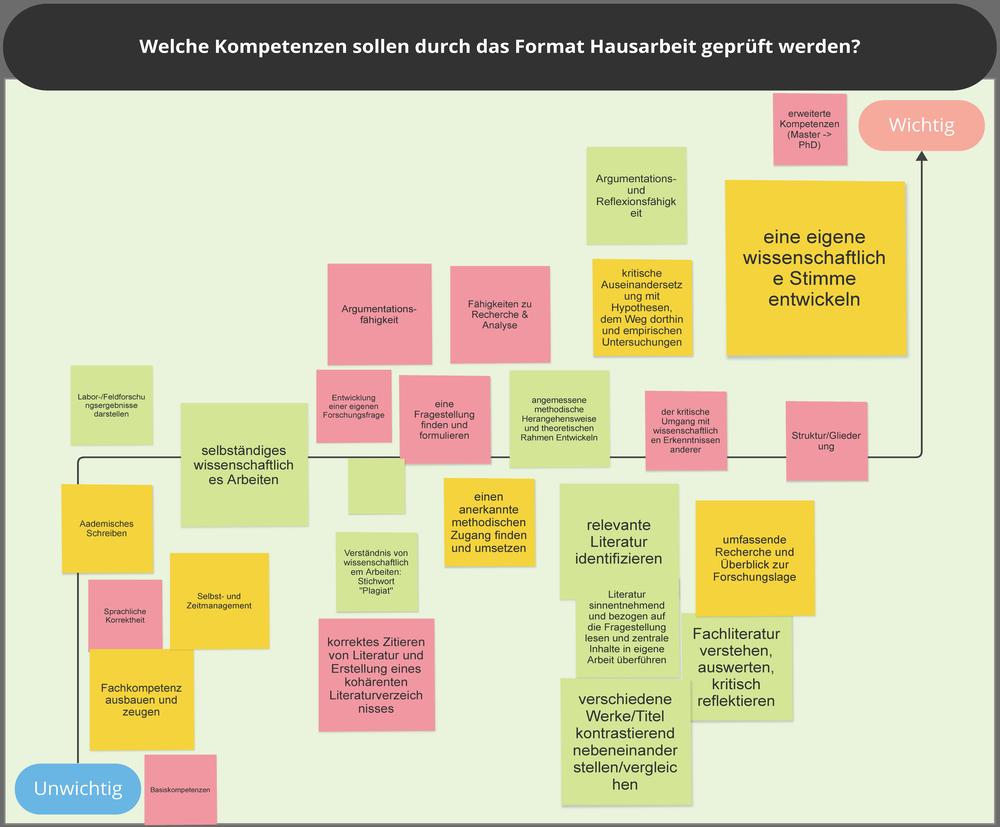
- Welche Kompetenzen sollen durch das Format Hausarbeit geprüft werden? (Board 4)
Für jede dieser Fragen gibt es eine eigene Pinnwand, in der die einzelnen Beiträge durch die Platzierung zusätzlich gewichtet werden können. Es werden Teilgruppen-Sitzungen eingerichtet, in denen die Teilnehmenden die verschiedenen Fragen diskutieren und Beiträge gemeinsam erarbeiten. Den Teilnehmenden ist es dabei auch möglich, die Gruppen zu wechseln und so mehrere oder auch alle Fragen gleichermaßen zu bearbeiten. Im Anschluss an die Arbeitsphase werden die Ergebnisse auf den Pinnwänden im Plenum vorgestellt und gemeinsam analysiert.
Dabei wird deutlich, dass spezielle Kompetenzen notwendig sind, um LLMs überhaupt in der wissenschaftlichen Textproduktion sinnvoll einsetzen zu können. So werden auf der entsprechenden Pinnwand sowohl Fähigkeiten in Bezug auf LLMs als auch fachlich-wissenschaftliche Fähigkeiten betont (Board 2: Kompetenzen für LLM-Einsatz). Um LLMs für die wissenschaftliche Textproduktion zu nutzen braucht es demnach Kenntnis über die Funktionsweise der genKI-Tools, die Kompetenz effektive Prompts zu entwickeln, aber auch ein generelles Fachwissen in Bezug auf wissenschaftliche Sprache.
Zudem wird diskutiert, inwiefern sich die im Format Hausarbeit vermittelten wissenschaftlichen Kernkompetenzen wie Entwicklung eines Forschungsdesigns, kritische Auseinandersetzung mit einer Thematik und evidenzbasiertes wissenschaftliches Argumentieren (Board 3: Welche Kompetenzen vermittelt die Hausarbeit) auch durch die Prüfungsform Hausarbeit überprüfen lassen (Board 4: Welche Kompetenzen werden durch Hausarbeit geprüft). Prozessual vermittelte Kompetenzen sind schwierig in einer singulären Prüfungsleistung zu bewerten. Deshalb ist es wichtig, die Hausarbeit nicht als isolierte Prüfungsform, sondern im Kontext der jeweiligen Ausbildungsphase und der damit verbundenen Lernziele (Kompetenzentwicklung) zu betrachten.
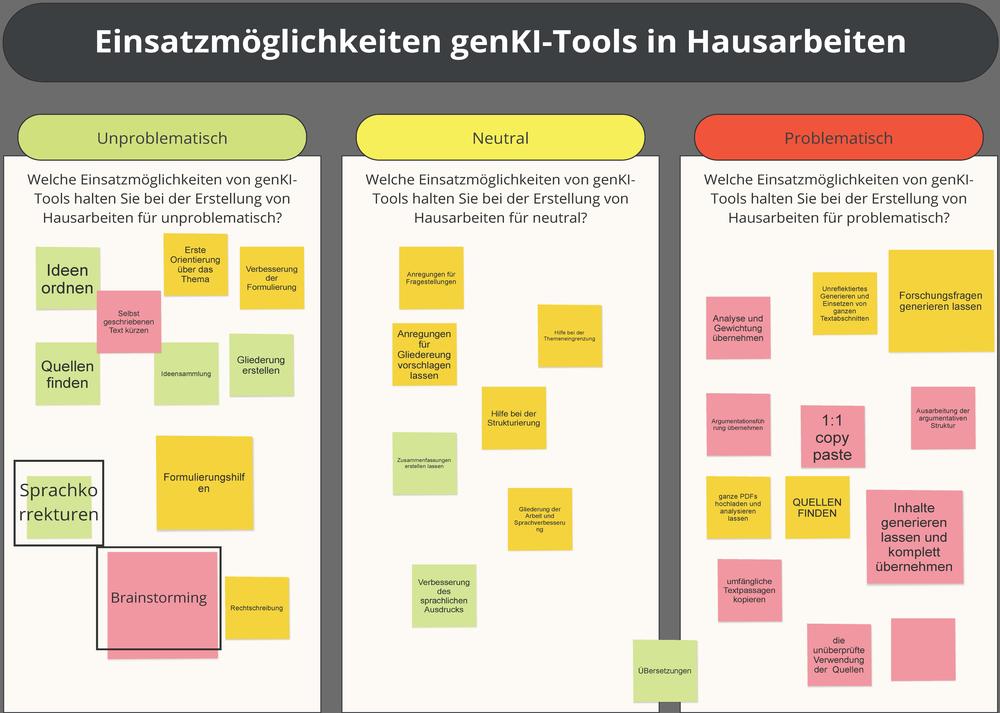
Um den Workshop abzuschließen, werden Einsatzmöglichkeiten generativer KI-Tools in Hausarbeiten innerhalb einer kurzen Arbeitsphase bewertet. Dazu werden die unterschiedlichen Aspekte auf einer Pinnwand den Spalten „unproblematisch“, „neutral“ und „problematisch“ zugeordnet (Board 5: Einsatzmöglichkeiten genKI). Als unproblematisch werden jene Einsatzbereiche gesehen, in denen die genKI-Tools verwendet werden, um bereits vorhandenes Material zu verbessern (z.B. Verbesserung oder Kürzung von Text, Ordnen oder Gliedern von Ideen,). Dem entgegen stehen die problematischen Einsatzbereiche, in denen die genKI-Tools als Ghostwriter fungieren und z.B. von der Forschungsfrage bis zur fertigen Arbeit der produzierte Text eins zu eins übernommen wird. Besondere Vorsicht ist bei der Suche nach Quellen geboten, da LLMs wahrscheinliche Sprachzusammenhänge generieren und so Quellen halluzinieren, die es in der Form nicht gibt. Hier zeigt sich die Notwendigkeit weiterer Aufklärungsarbeit im Bereich generativer KI und LLMs (der Einsatzbereich „Quellen finden“ wird von einigen als problematisch, von anderen allerdings als unproblematisch eingeordnet).
Take-aways
Der Einsatz von LLMs für die wissenschaftliche Textproduktion ist voraussetzungsreich und erfordert spezifische Kompetenzen, die neben die klassischen fachspezifischen Kompetenzen treten und speziell geschult werden müssen.
Die Hausarbeit ist keine punktuelle Prüfungsleistung, sondern Produkt eines Arbeitsprozesses, welcher in seinen verschiedenen Phasen ein breites Kompetenzspektrum bedient, das die Studierenden zu eigenem wissenschaftlichen Arbeiten befähigen soll. Hierzu gehören insbesondere Fach- und Methodenkompetenz, die sowohl Voraussetzung für sinnvolles, problemlösungsorientiertes Prompting sind, als auch für die qualitative Beurteilung KI-generierter Inhalte.
ChatGPT und Co. - Das Ende der Hausarbeit? © 2024 by Armin Glatzmeier (FU Berlin) is licensed under CC BY-NC-ND 4.0.